
Media and Entertainment
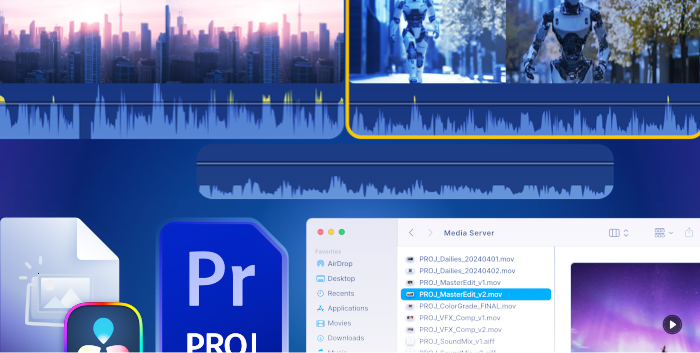
The "declouding" myth: Why hybrid is the new default, not a retreat.Is the industry "leaving the cloud"? If you look at the headlines, you might think so. Terms like "repatriation" and "declouding" are being tossed around boardrooms as organizations balk at their monthly AWS or Azure bills.
Read more








.jpeg)









