
What we’ve learned from 50+ AI startups about infrastructure bottlenecks.
“We had credits. We had funding. But nobody—not AWS, not CoreWeave, not Lambda—had the GPUs we actually needed at a price we could justify.”
Some teams were just coming off their raise and needed to get a POC into production. Others had already launched and were scaling fast. A few were quietly growing and preparing for real traction. What they had in common was this: infrastructure decisions suddenly mattered, and most didn’t have the time, flexibility, or internal resources to get them right the first time.
This post breaks down the most common patterns we’ve seen: what slows teams down, how they’re solving it, and what comes next.
What we’re seeing across the market.
AI startups tend to fall into one of three categories when it comes to infrastructure:
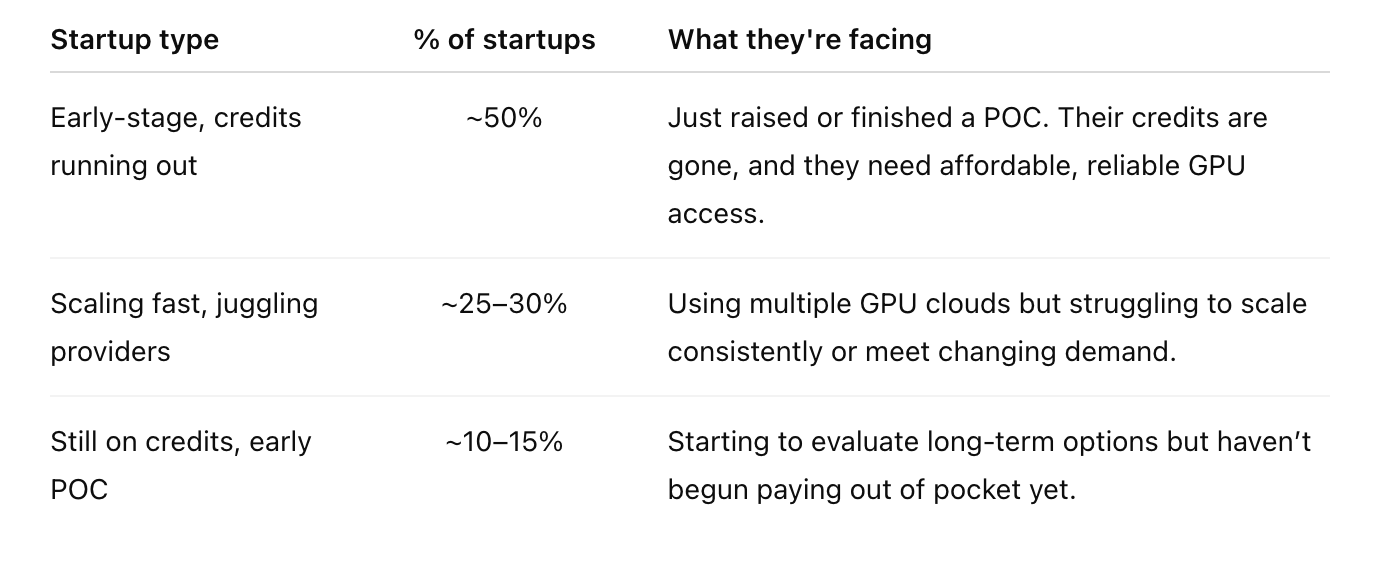
Some teams are just getting started. Their credits are gone, and the clock is ticking. Others are scaling fast and need reserved clusters that can actually keep up. Some have multiple providers in place but still can’t get the right GPUs in the right region at the right time.
While the use case varies, the sequence is often the same. First comes a scramble for access: H100s, A100s, or 4090s in specific regions. Then comes inefficiency—underutilized clusters, mismatched GPU types, or scaling issues beyond 8× configurations. Finally, storage bottlenecks emerge: slow access to training data, lack of persistent volumes, or clunky file mounts that break under load.
How the pain shows up.
Most teams don’t need a dedicated infra hire to know when something’s off. The friction is obvious from the start. And for many, it follows a familiar pattern.
Step 1: Access is the first wall.
The moment startup credits run out, list pricing becomes a dealbreaker. Even before that, teams often know exactly what GPU they need—maybe an H100 for training or a few 4090s for inference—but can’t find them in stock. Capacity is limited. Regional availability is inconsistent. Quota approvals and support responses can take days. This is usually when teams start looking for alternatives.
Step 2: Fit and scale become the next challenge.
Once a team gets online, new questions arise. Are the clusters sized correctly? Is the workload making full use of the allocated GPUs? Can we scale to 8×H100s in Europe by tomorrow, or will we hit a provisioning wall? Teams often realize they’re overpaying for underused resources or locked into configs that don’t flex with their workload. The infra is up, but it’s not efficient.
Step 3: Storage and data access start to slow things down.
As training jobs ramp and pipelines mature, new friction emerges. Teams ask how to get faster access to large datasets, whether persistent storage can be attached, and how to avoid clunky file mounts that break under load. These issues usually don’t show up until compute is flowing—but when they do, they can block progress just as hard as GPU shortages did early on.
4 GPU bottlenecks we hear every week.
If any of these sound familiar, you’re not alone.
Even with budget or credits, teams get stuck waiting.
Most AI startups start with AWS, CoreWeave, or Lambda. But when it’s time to scale, the specific GPUs they need—H100s in the right region, A100s at the right price—just aren’t there. Some get stuck waiting on quota approvals. Others file support tickets that go unanswered. And some just watch a waitlist grow longer while deadlines loom.
“We had startup credits and a deadline. But every H100 request hit a waitlist.”
Many are stuck using the wrong GPUs for the job.
It’s surprisingly common. Teams using A100s for diffusion jobs just because they’re available. Paying for 4090s when a 5090 would’ve been faster and cheaper. Without an easy way to test and compare configs, it’s hard to know what fits best—and even harder to course-correct once the jobs are running.
“We weren’t sure what config we needed, so we overbuilt and paid the price.”
Idle clusters burn through budgets.
Teams often set up expensive clusters, only to realize they’re running at half capacity. Or they’re forced to juggle smaller, single-GPU nodes because multi-GPU instances weren’t available when they needed them. Either way, the result is the same: wasted spend and slow progress.
“We were paying Lambda rates but using a fraction of the power. It didn’t scale.”
Scaling friction kills momentum.
Some teams get one cluster running and then immediately hit a wall trying to expand. Regional availability, launch delays, or rigid provider configs all slow things down. If you need to spin up 4×H100s by tomorrow and your provider can’t make it happen, your roadmap slips.
“We’re scaling every week. If we can’t get 4×H100s by tomorrow, we’re blocked.”
Two common buyer patterns.
Across the 50+ AI startups we’ve worked with, two patterns show up again and again.
The first: Teams who just raised, or just ran out of credits.
They’ve reached a turning point—ready to go from experimentation to production—but now face real infrastructure decisions. These teams usually know what they want: H100s, H200s, maybe 5090s. What they don’t want is to burn their budget on list pricing or overpay for stopgap setups.
“We couldn’t afford list prices. We needed a long-term home for our workloads.”
The second: Teams scaling fast across multiple providers.
These are teams already using Lambda, RunPod, CoreWeave, or a mix of them. Their needs change quickly—new models, new regions, new demand spikes. They’re not always switching everything over, but when something matters, they need a provider they trust to deliver.
“We didn’t switch everything over, but we trust you with what matters most.”
What startups do instead.
When teams hit these walls, they reach out. Sometimes it’s right after their credits run out. Sometimes it’s mid-sprint, when their current provider can’t deliver. Either way, the first ask is always the same: “Can you get us what we need?”
That usually means H100s, 5090s, or H200s—in the right regions, without a waitlist, ticket queue, or quota approval saga. But getting access is just the start. Most teams are also looking for help figuring out what setup actually makes sense for their workloads. They don’t want to overbuild. They don’t want to waste budget. And they don’t want to spend another week benchmarking GPUs they might not even be able to find.
For example, one startup was paying premium prices for multi-GPU clusters that were rarely hitting 50% utilization. After a quick benchmarking session, they pivoted to a setup that ran on 4090s at half the cost—and finished jobs 30% faster. That kind of outcome is what keeps teams coming back.
As one founder put it, “You didn’t just give us a cluster. You helped us figure out what would actually work.”
What kind of setup fits you?
Most teams we work with fall into one of three GPU usage patterns—and each needs something a little different.
- Foundation model training or RLHF? You probably need long-running clusters of 8× or more. We often help teams set up H100 or H200 machines in bulk, and can reserve them across regions to avoid scaling friction later.
- Fine-tuning or RAG at smaller scale? A handful of 4090s might hit your price/performance sweet spot. These are ideal for iterative workflows and bursty demand—without paying for idle capacity.
- Model deployment and inference? You likely care most about predictable access and cost. In that case, we’ll help you benchmark options and find the best-fit config—whether that’s 5090s for speed or A100s for consistency.
Not sure where you land? That’s common. We can walk you through it.
What happens after that first win.
For some teams, the first win is getting their very first job out of the queue—fast, affordable, and headache-free. For others, it’s finding a more reliable provider that can actually keep up with demand.
But once things are running, the same pattern plays out. Teams start asking:
- Can we run inference jobs here too?
- What if we need another region?
- Can you help with storage or data access?
We’ve seen it happen again and again: a single urgent job turns into something bigger. Within weeks, teams are scaling across regions, expanding workloads, and leaning on us for more of their stack.
From first cluster to full stack.
Most teams come to us with one urgent need: the right GPU, right now. But that’s rarely where it ends.
Once compute is running smoothly, new needs emerge. Teams ask for object storage that scales with their datasets. File access that works like a local system—fast, familiar, and built for collaboration. Infrastructure that grows with them, without slowing them down.
That’s the quiet power of the platform. You start with compute. You grow into the stack.
And for VCs evaluating our business, this is what makes the model powerful. Each urgent job we help unlocks a long-term, high-value infrastructure relationship.
Ready to see what’s possible?
If you’re running into GPU headaches—or just want to know what setup makes the most sense for your next job—we’d love to help.



